LLM infrastructureinfrastructure that
grows with your
One SDK that gives you observability, prompt management, and evals for every LLM call. Install it with your first provider. The rest shows up when you need it.
Start small!
One package. That's all you require to get started.
Add the SDK to your project.
Create a client — zero config needed.
import { Hono } from 'hono'; import { stream } from 'hono/streaming'; import { streamText } from 'ai'; import { createOpenAI } from '@ai-sdk/openai'; import { llmops } from '@llmops/sdk'; const llmopsClient = llmops(); const openai = createOpenAI(llmopsClient.provider()); const app = new Hono(); app.get('/', async (c) => { const result = streamText({ model: openai.chat('@google/gemini-2.5-flash'), prompt: 'What model are you?', }); return stream(c, async (stream) => { for await (const part of result.textStream) { await stream.write(part); } }); });
Route to any model through a unified interface.
Prompt: What model are you?
Any provider, any model — one SDK.
Any provider, any model — one SDK.
Scale your providers
Organize multiple LLM providers with custom slugs. One config, many models.
Register providers with custom slugs.
import { llmops } from '@llmops/sdk'; const ops = llmops({ providers: { 'openai-prod': { type: 'openai', apiKey: process.env.OPENAI_API_KEY, }, 'anthropic-dev': { type: 'anthropic', apiKey: process.env.ANTHROPIC_API_KEY, }, }, });
 OpenAI
OpenAI Anthropic
Anthropic Google
Google Mistral
Mistral Cohere
Cohere AWS Bedrock
AWS Bedrock Azure
Azure Groq
Groq DeepSeek+68 more
DeepSeek+68 moreOne config. Any model. Any provider.
import { llmops } from '@llmops/sdk'; const ops = llmops({ providers: { 'openai-prod': { type: 'openai', apiKey: process.env.OPENAI_API_KEY, }, 'anthropic-dev': { type: 'anthropic', apiKey: process.env.ANTHROPIC_API_KEY, }, }, });
Name your providers with custom slugs.
Separate credentials per environment.
OpenAIAnthropicGoogleMistralCohereAWS BedrockAzureGroqDeepSeek+68 moreExplore Visually
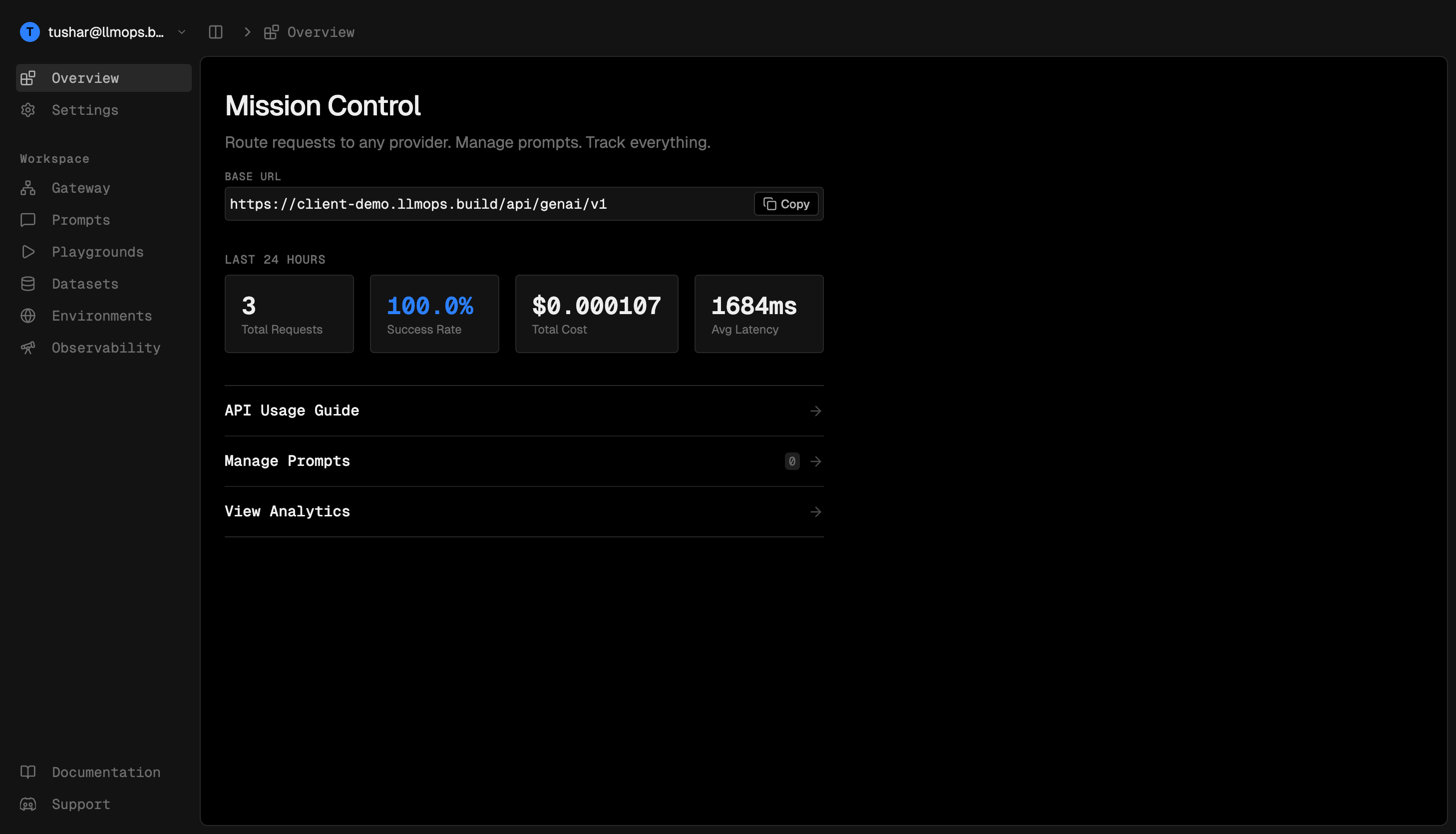
Connect a database, mount the middleware, and a full dashboard appears at /llmops.
Connect a Postgres database to store everything.
import { llmops } from '@llmops/sdk'; import { Pool } from 'pg'; export default llmops({ database: new Pool({ connectionString: process.env.DATABASE_URL, }), // ... });
Mount the middleware — the dashboard is served automatically.
import { Hono } from 'hono'; import { createLLMOpsMiddleware } from '@llmops/sdk/hono'; import ops from './llmops'; const app = new Hono(); app.use('/llmops/*', createLLMOpsMiddleware(ops)); export default app;
import { llmops } from '@llmops/sdk'; import { Pool } from 'pg'; export default llmops({ database: new Pool({ connectionString: process.env.DATABASE_URL, }), // ... });
import { Hono } from 'hono'; import { createLLMOpsMiddleware } from '@llmops/sdk/hono'; import ops from './llmops'; const app = new Hono(); app.use('/llmops/*', createLLMOpsMiddleware(ops)); export default app;
Connect a Postgres database to store everything.
Mount the middleware — the dashboard is served automatically.
See Everything
Every request is logged automatically. Costs, latency, tokens — all tracked without extra code.
$12.84
$8.21
1.2M tokens$4.63
340K tokens847
Version Your Prompts
Manage prompts from the UI and iterate without redeploying. Reference them by name in your API calls.
GPT 4oactiveYou are a helpful assistant. Greet {{userName}} warmly and ask how you can help today.
Gemini 2.5 FlashAssist {{userName}} with their query. Be concise and friendly.
Claude Sonnet 4.5You are a chatbot. Help the user.
import { streamText } from 'ai'; import { openai } from './providers'; const result = await streamText({ model: openai.chat('@openai/gpt-4o'), headers: { 'x-llmops-prompt': 'my-chatbot-prompt', }, variables: { userName: 'Alice' }, });
GPT 4oactiveYou are a helpful assistant. Greet {{userName}} warmly and ask how you can help today.
Gemini 2.5 FlashAssist {{userName}} with their query. Be concise and friendly.
Claude Sonnet 4.5You are a chatbot. Help the user.
import { streamText } from 'ai'; import { openai } from './providers'; const result = await streamText({ model: openai.chat('@openai/gpt-4o'), headers: { 'x-llmops-prompt': 'my-chatbot-prompt', }, variables: { userName: 'Alice' }, });